Partie 14 : L’indexation spatiale¶
Rapellez-vous que l’indexation spatiale est l’une des trois fonctionnalités clés d’une base de données spatiales. Les index permettent l’utilisation de grandes quantités de données dans une base. Sans l’indexation, chaque recherche d’entité nécessitera d’accéder séquentiellement à tous les enregistrements de la base de données. L’indexation accélère les recherches en organisant les données dans des arbres de recherche qui peuvent être parcourus efficacement pour retrouver une entité particulière.
L’indexation spatiale l’un des plus grands atouts de PostGIS. Dans les exemples précédents, nous avons construit nos jointures spatiales en comparant la totalité des tables. Ceci peut parfois s’avérer très coûteux : réaliser la jointure de deux tables de 10000 enregistrements sans indexation nécessitera de comparer 100000000 valeurs, les comparaisons requises ne seront plus que 20000 avec l’indexation.
Lorsque nous avons chargé la table nyc_census_blocks, l’outil pgShapeLoader crée automatiquement un index spatial appelé nyc_census_blocks_the_geom_gist.
Pour démontrer combien il est important d’indexer ses données pour la performance des requêtes, essayons de requêter notre table nyc_census_blocks sans utiliser notre index.
La première étape consiste à supprimer l’index.
DROP INDEX nyc_census_blocks_the_geom_gist;
Note
La commande DROP INDEX supprime un index existant de la base de données. Pour de plus amples informations à ce sujet, consultez la documentation officielle de PostgreSQL.
Maintenant, regardons le temps d’exécution dans le coin en bas à droite de l’interface de requêtage de pgAdmin, puis lançons la commande suivante. Notre requête recherche les blocs de la rue Broad.
SELECT blocks.blkid
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.the_geom, subways.the_geom)
WHERE subways.name = 'Broad St';
blkid
-----------------
360610007003006
La table nyc_census_blocks est très petite (seulement quelque milliers d’enregistrements) donc même sans l’index, la requête prends 55 ms sur l’ordinateur de test.
Maintenant remettons en place l’index et lançons de nouveau la requête.
CREATE INDEX nyc_census_blocks_the_geom_gist ON nyc_census_blocks USING GIST (the_geom);
Note
l’utilisation de la clause USING GIST spécifie à PostgreSQL de créer une structure (GIST) pour cet index. Si vous recevez un message d’erreur ressemblant à ERROR: index row requires 11340 bytes, maximum size is 8191 lors de la création, cela signifie sans doute que vous avez omis la clause USING GIST.
Sur l’ordinateur de test le temps d’exécution se réduit à 9 ms. Plus votre table est grande, plus la différence de temps d’exécution pour une requête utilisant les index augmentera.
Comment les index spatiaux fonctionnent¶
Les index des bases de données standards créent des arbres hiérarchiques basés sur les valeurs des colonnes à indexer. Les index spatiaux sont un peu différents - ils ne sont pas capables d’indexer des entités géométriques elles-même mais ils indexent leur étendues.
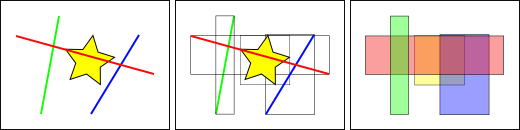
Dans la figure ci-dessus, le nombre de lignes qui intersectent l’étoile jaune est unique, la ligne rouge. Mais l’étendue des entités qui intersectent la boîte jaune sont deux, la boîte rouge et la boîte bleue.
La manière dont les bases de données répondent de manière efficace à la question “Quelles lignes intersectent l’étoile jaune ?” correspond premièrement à répondre à la question “Quelle étendue intersecte l’étendue jaune” en utilisant les index (ce qui est très rapide) puis à calculer le résultat exact de la question “Quelles lignes intersectent l’étoile jaune ?” seulement en utilisant les entités retournées par le premier test.
Pour de grandes tables, il y a un système en “deux étapes” d’évaluation en utilisant dans un premier temps l’approximation à l’aide d’index, puis en réalisant le test exact sur une quantité bien moins importante de données ce qui réduit drastiquement le temps de calcul nécessaire à cette deuxième étape.
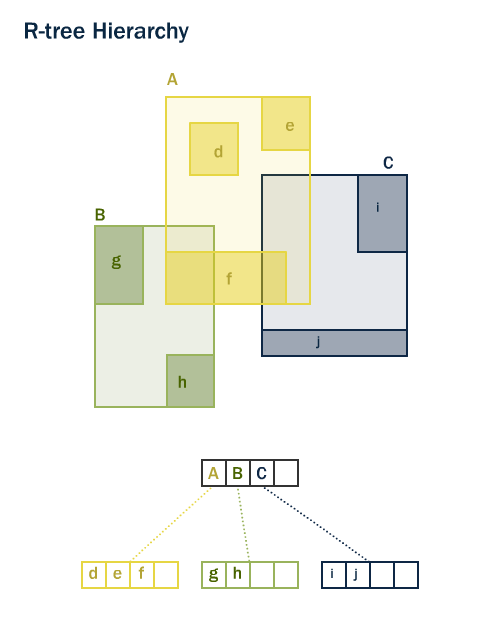
PotGIS et Oracle Spatial partage la même notion d’index structuré sous la forme “d’arbres R” [1]. Les arbres R classent les données sous forme de rectangles, de sous-rectangles etc. Cette structure d’index gère automatiquement la densité et la taille des objets.
Requête avec seulement des index¶
La plupart des fonctions utilisées par PostGIS (ST_Contains, ST_Intersects, ST_DWithin, etc) prennent en compte les index automatiquement. Mais certaines fonctions (comme par exemple : ST_Relate) ne les utilisent pas.
Pour utiliser une recherche par étendue utilisant les index (et pas de filtres), vous pouvez utiliser l’opérateur &&. Pour les géométries, l’opérateur && signifie “l’étendue recouvre ou touche” de la même manière que l’opérateur = sur des entiers signifie que les valeurs sont égales.
Essayons de comparer une requête avec seulement un index pour la population du quartier ‘West Village’. En utilisant la commande && notre requête ressemble à cela :
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.the_geom && blocks.the_geom
WHERE neighborhoods.name = 'West Village';
50325
Maintenant essayons la même requête en utilisant la fonction plus précise ST_Intersects.
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.the_geom, blocks.the_geom)
WHERE neighborhoods.name = 'West Village';
27141
Un plus faible nombre de résultats ! La première requête nous renvoie tous les blocs qui intersectent l’étendue du quartier, la seconde nous renvoie seulement les blocs qui intersectent le quartier lui-même.
Analyse¶
Le planificateur de requête de PostgreSQL choisit intelligemment d’utiliser ou non les index pour réaliser une requête. Il n’est pas toujours plus rapide d’utiliser un index pour réaliser une recherche : si la recherche doit renvoyer l’ensemble des enregistrements d’une table, parcourir l’index pour récupérer chaque valeur sera plus lent que de parcourir linéairement l’ensemble de la table.
Afin de savoir dans quelle situation il est nécessaire d’utiliser les index (lire une petite partie de la table plutôt qu’une grande partie), PostgreSQL conserve des statistiques relatives à la distribution des données dans chaque colonne indexée. Par défaut, PostgreSQL rassemble les statistiques sur une base régulière. Néanmoins, si vous changez dramatiquement le contenu de vos tables dans une période courte, les statistiques ne seront alors plus à jour.
Pour vous assurez que les statistiques correspondent bien au contenu de la table actuelle, il est courant d’utiliser la commande ANALYZE après un grand nombre de modifications ou de suppression de vos données. Cela force le système de gestion des statistiques à récupérer l’ensemble des données des colonnes indexées.
La commande ANALYZE demande à PostgreSQL de parcourir la table et de mettre à jour les statistiques utilisées par le planificateur de requêtes (la planification des requêtes sera traité ultérieurement).
ANALYZE nyc_census_blocks;
Néttoyage¶
Il est souvent stressant de constater que la simple création d’un index n’est pas suffisant pour que PostgreSQL l’utilise efficacement. Le nettoyage doit être réalisé après qu’un index soit créé ou après un grand nombre de requêtes UDATE, INSERT ou DELETE ait été réalisé sur une table. La commande VACUUM demande à PostgreSQL de récupérer chaque espace non utilisé dans les pages de la table qui sont laissées en l’état lors des requêtes UPDATE ou DELETE à cause du modèle d’estampillage multi-versions.
Le nettoyage des données est tellement important pour une utilisation efficace du serveur de base de données PostgreSQL qu’il existe maintenant une option “autovacuum”.
Activée par défaut, le processus autovacuum nettoie (récupère l’espace libre) et analyse (met à jour les statistiques) vos tables suivant un intervalle donné déterminé par l’activité des bases de données. Bien que cela fonctionne avec les bases de données hautement transactionnelles, il n’est pas supportable de devoir attendre que le processus autovacuum se lance lors de la mise à jour ou la suppression massive de données. Dans ce cas, il faut lancer la commande VACUUM manuellement.
Le nettoyage et l’analyse de la base de données peuvent être réalisés séparément si nécessaire. Utiliser la commande VACUUM ne mettra pas à jour les statistiques alors que lancer la commande ANALYZE ne récupèrera pas l’espace libre des lignes d’une table. Chacune de ces commandes peut être lancée sur l’intégralité de la base de données, sur une table ou sur une seule colonne.
VACUUM ANALYZE nyc_census_blocks;
Liste des fonctions¶
geometry_a && geometry_b: retourne TRUE si l’étendue de A chevauche celle de B.
geometry_a = geometry_b: retourne TRUE si l’étendue de A est la même que celle de B.
ST_Intersects(geometry_a, geometry_b): retourne TRUE si la géométrie a “intersecte spatialement” la géométrie ‘b- (si elles ont une partie en commun) et FALSE sinon (elles sont disjointes).
Notes de bas de page
| [1] | http://postgis.org/support/rtree.pdf |